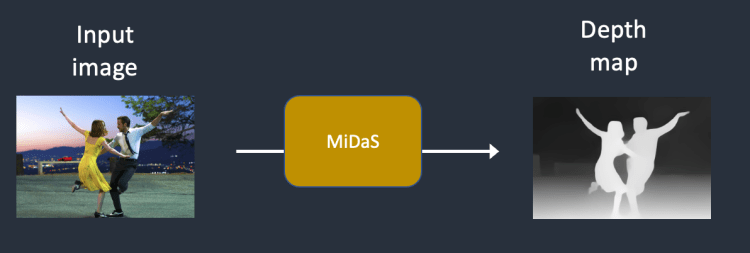
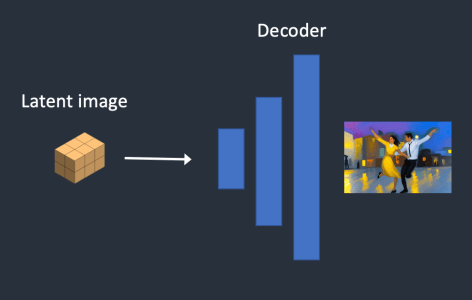
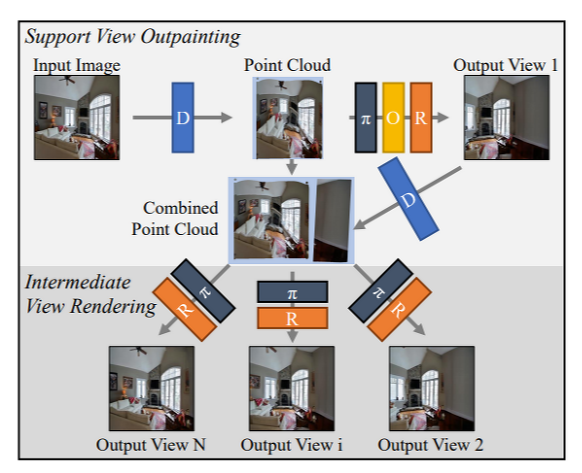
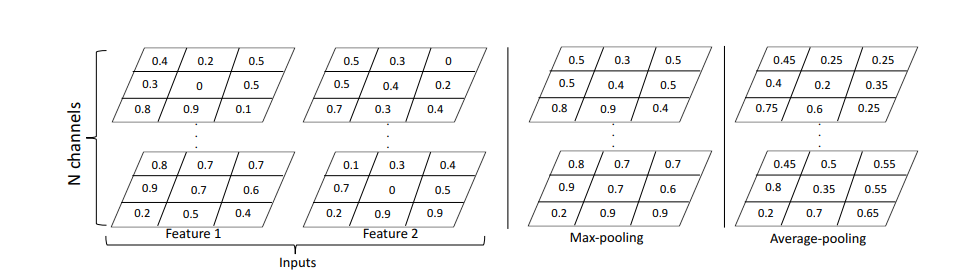
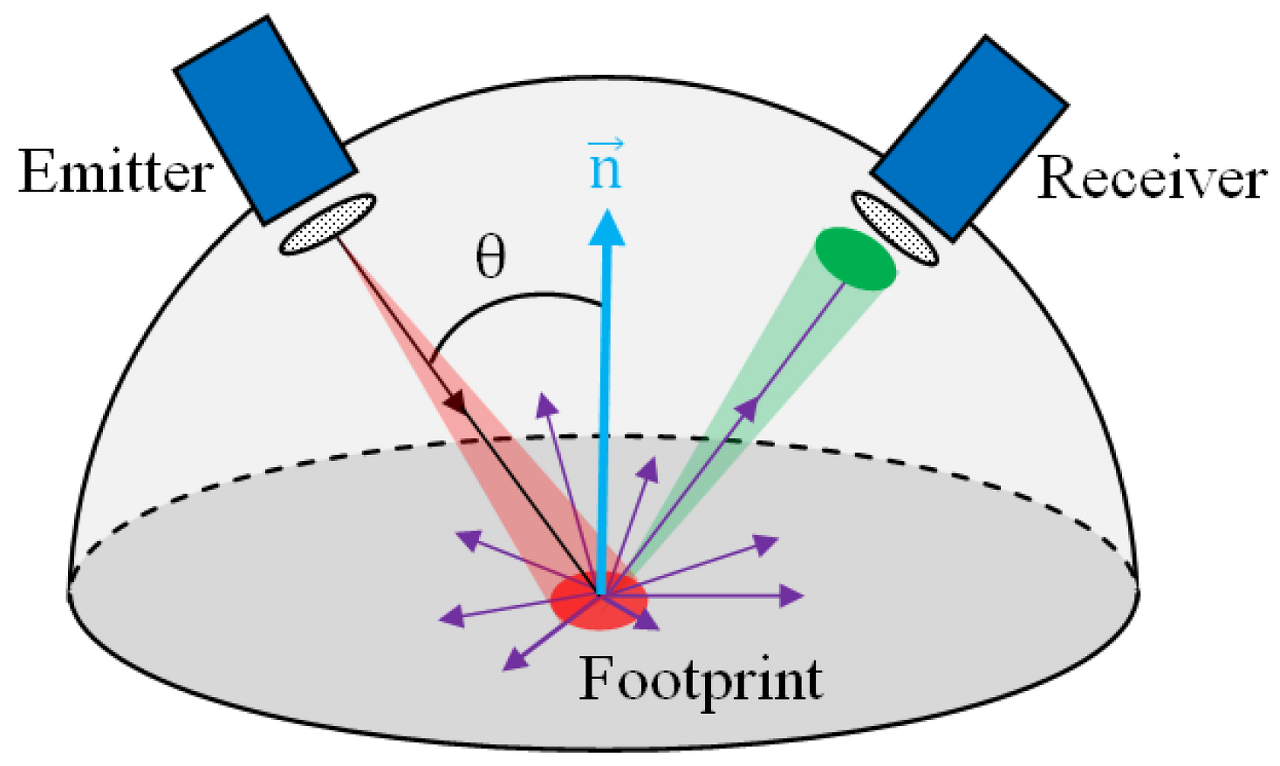
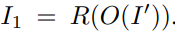바깥 view를 생성하는 가장 대표적인 novel view synthesis 모델이라고 할 수 있다.
2020년 CVPR에 등재되었다.
Introduction
기존 방법들의 한계:
- multiple views
- occluded object를 추적하는 데 좋음
- But applicability가 떨어짐 (여러 view에서 사진 찍어야 됨)
- training a convolutional network to estimate depth from images
- single-image view synthesis가 가능해짐 --> 왜 그런지에 대한 추가 조사 필요
- GT depth map이 학습에 필요함, 더불어 학습된 데이터가 실내면 실외에서는 성능이 안 좋음 (lack of generalization)
- utilzing 3D-aware intermediate representations
- 학습 동안에 3D information을 사용하지 않음
- 3D information와 3D-aware intermediate representation의 차이에 대해서 궁금해서 search를 해보았지만 정확한 정보를 얻을 수 없었다. 나의 뇌피셜이지만 두 정보의 차이는 3D cordinates 같은 full 정보를 encoding하느냐 아니면 voxel이나 point cloud처럼 3D 구조의 일부 정보를 indirectly하게 포함하느냐인 것인 거 같다. (partiality of 3D information) --> 확인 필요
- 대신, end-to-end 생성 모델과 3D-aware intermediate representations을 사용하여 image supervision만으로도 학습이 가능
- single object로 이루어진 합성 scene에 대해서 좋은 성능을 보임
- 하지만 복잡한 real-world scene에 대해서는 낮은 성능을 보임
- 학습 동안에 3D information을 사용하지 않음
SynSin은 end-to-end model로 GT 3D supervsion 없이 학습이 가능함. 더불어 3D scene sturucture을 high-resolution point cloud로 표현함.
- point cloud는 "3D 공간에서 점의 모음으로 3D 장면이나 객체를 나타내는 3D-aware intermediate representation" 으로 https://23min.tistory.com/8에 잘 정리되어 있다.
'Novel View Synthesis' 카테고리의 다른 글
| [논문 리뷰] Text2Room: Extracting Textured 3D Meshes from 2D Text-to-Image Models (0) | 2023.06.07 |
|---|---|
| [논문 리뷰] SceneScape: Text-Driven Consistent Scene Generation (0) | 2023.06.05 |
| [배경 지식] depth-conditioned image generation (0) | 2023.06.02 |
| [배경 지식] Depth - Stable Diffusion (0) | 2023.06.01 |
| [논문 리뷰] PixelSynth: Generative a 3D-Consistent Experience from a Single Image (0) | 2023.05.24 |